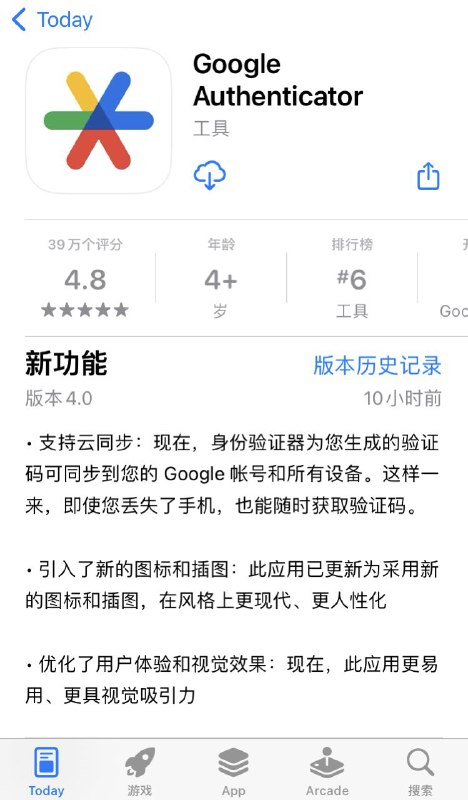
Appinn Feed|小众软件

- 太惨了

- 彭博社 的一篇文章《人工智能的未来依赖于高中教师的免费数据库》称:
一名德国高中老师 Christoph Schuhmann 创立了一个名为“Large-scale AI Open Network”(LAION)的免费AI训练数据集。该数据集已经包含了超过50亿张图片,并被广泛应用于训练文本到图像生成器,如Google的Imagen和Stable Diffusion。Schuhmann和他的志愿者团队从各大网站如Pinterest、Shopify和亚马逊网络服务等爬取了大量图像,并与之关联描述性文本,最终形成了目前最大的免费图像和标题数据集。此举引发了一系列道德和法律问题,例如是否可以利用公共可用的材料来构建数据库,以及这些创作者是否应该得到报酬。虽然Stability AI和Midjourney等公司因版权侵犯而面临诉讼,但Schuhmann并不担心这些问题,他只想将数据开放出来。
摘要来自 ChatGPT